힙(Heap) 자료구조란 ?
1. 힙(Heap) 자료구조의 정의
- 힙 자료구조는 '완전 이진 트리' 를 기초로 하는 자료 구조
- 이때, 완전 이진 트리는 '마지막을 제외한 모든 노드에서 자식들이 꽉 채워진 이진 트리' 이다.
2. 의의
- 힙은 수의 집합에서 가장 작은 수나, 가장 큰 수만을 꺼낼 때 유용한 자료 구조이다.
힙(Heap) 의 특징
1. 힙 = [최대 힙(Max Heap)] + [최소 힙(Min Heap)] 으로 나누어 진다.
1) 최대 힙
- 부모 노드의 값 > 자식 노드의 값

2) 최소 힙
- 부모 노드의 값 < 자식 노드의 값

-> 힙은 항상 느슨한 정렬 상태(반 정렬 상태)를 유지한다.
2. 힙은 '중복 값' 을 허용
- 힙은 최댓값 or 최솟값을 쉽게 뽑기 위한 자료구조로, 중복을 허용한다.
힘(Heap) 의 성질
1. n 개의 노드를 가진 힙은 정확히 '하나'만 있고,
그 힙(트리)의 높이(height)는 |log2^n|
2. 힙의 한 노드와 + 그 노드의 자손 노드들로 이루어진 부분 트리(subtree) => 힙
3. 최대 힙의 경우, 힙의 루트 노드는 항상 최댓값을 저장
힙(Heap) 의 배열 표현
1. 힙의 배열 표현 시 저장 방법
1) 힙은 완전 이진 트리로, 배열 표현 시 가독성을 위해 인덱스 1 부터 사용한다.
-> A[0] 은 비워두고, A[1] 부터 A[n] 에 힙의 노드들을
[위 층에서 -> 아래 층으로 / 같은 층에서는, 왼쪽에서 -> 오른쪽] 순서대로 저장
2) 루트 노드의 인덱스 i = 1 인 경우, 아래와 같이 나타낼 수 있다.
| 노드 위치 | 인덱스 |
| 노드 i 의 부모 노드 | i / 2 |
| 노드 i 의 왼쪽 자식 노드 | 2 * i |
| 노드 i 의 오른족 자식 노드 | 2 * i + 1 |
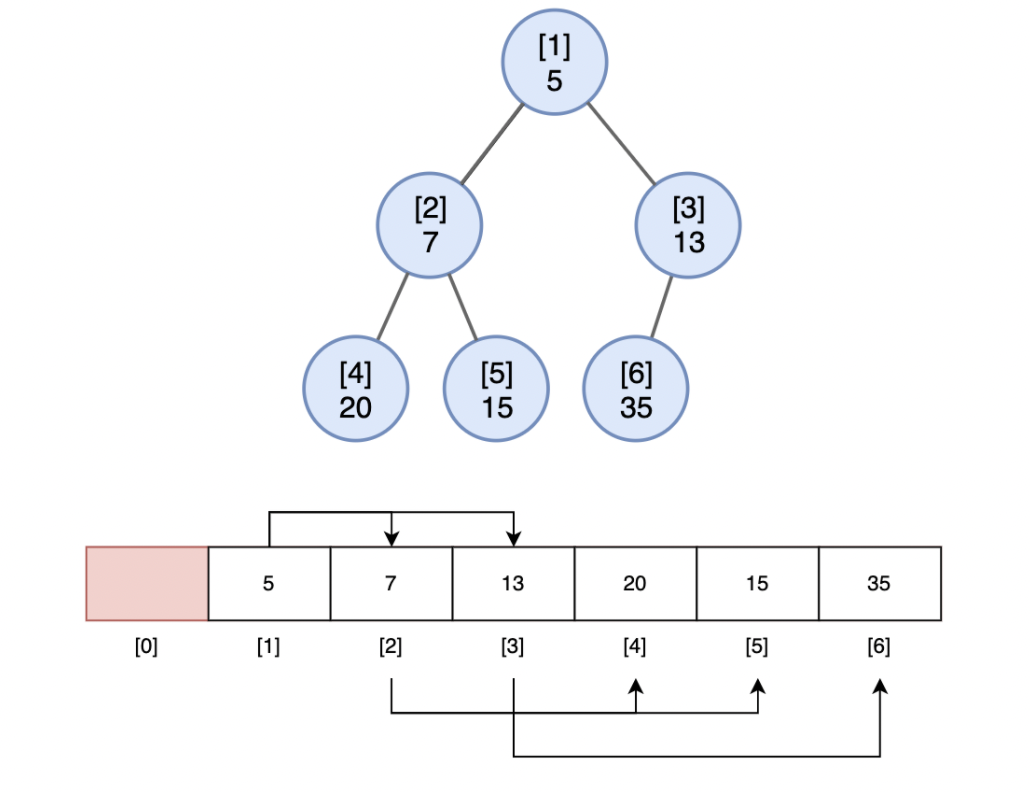
2. 힙의 배열 표현 및 힙 조건
1) 힙의 내부 노드(Internal node) = 배열의 첫 [n/2] 개의 지수들에 저장
2) 힙의 리프 노드(Leaf node) = 배열의 마지막 [n/2] 개의 지수들에 저장


3) 배열의 앞쪽 반에 있는, 즉 내부 노드 요소 A[i] 는, A[2i]와 A[2i+1]보다 크거나 같다
| A[i] >= max(A[2i], A[2i+1]), 1 <= I <= [n/2] |
- 이때, 만약 2i+1 > n 이라면, 힙 조건은 A[i] >= A[2i] 이다.
- 이 경우, 노드 i 는 왼쪽 자식 노드만 있는 것
힙(Heap)의 연산
- 최대 힙을 기준으로, 이때 size = 힙의 원소 수로, 전역변수라 한다.
1. Heapify
(1) 정의
- 이진 트리에서 힙의 속성을 유지하는 작업을 하며,
- 위에서 -> 아래로 내려가며 작업을 한다.
- 최대 힙의 부모 노드는 항상 자식 노드의 값보다 크다는 조건을 가지고 있는데, 힙에서 삽입 or 삭제로 인해 최대 힙의 조건이 깨질 수
있으며, 이러한 상황에서 최대 힙의 조건을 만족할 수 있게 노드들의 위치를 바꾸어 가며 힙을 재구조화(Heapify) 하는 것이다.
- 삽입과 삭제 연산의 경우, 연산 자체는 O(1)의 시간복잡도로 동작하지만, Heapify 의 과정을 거치기 때문에 O(logN) 의 시간 복잡도
를 가지게 된다.
(2) 작업(수행) 순서
1) 요소의 값과 자식 노드의 값을 비교한다.
2) 만약, 자식 노드의 값이 크다면, 왼쪽과 오른쪽 자식 노드 중 '가장 큰 값'으로 교환한다.
3) 힙 속성이 유지될 때까지 1) 번과 2) 번의 과정을 반복한다.

(3) 시간 복잡도 : O(logN)
2. Build Heap
(1) 개념
- 완전 이진트리를 -> Heap 구조로 만드는 작업으로,

- 위의 그림과 같이, 루트 노드의 인덱스가 1인 경우 배열로 표현된 힙은 [n / 2 + 1 ~ n / 2 + n]까지 leaf node 라고 할 수 있다.
- leaf node를 제외한 나머지 노드 [1 ~ n / 2] 부분에 heapify 를 수행하면 heap 구조로 build 할 수 있다.
(2) 작업(수행) 순서
- 최대 힙으로 build 하는 과정을 아래 그림에서 보면,

(3) 시간 복잡도 : O(n)
3. Peek
(1) 개념
- Heap 에서 '최대 요소'를 반환하는 작업
- Max Heap 에서 최댓값은 항상 루트 -> 루트 값 반환
(2) 시간 복잡도 : O(1)
4. Extract
(1) 개념
- Heap 에 최대 요소를 추출하는 작업
(2) 작업(수행) 순서
1) Heap 의 최대 요소 = 루트 노드 -> 루트 노드의 값 추출
2) Heap 의 마지막 요소를 루트 노드에 배리
3) Heap 의 마지막 요소를 루트 노드에 배치 시 Heap 속성 위배 -> 루트 노드부터 max_heapify 수행

(3) 시간 복잡도 : O(logN)
5. Increase Value
(1) 개념
1) Max Heap에서 사용하는 작업으로, 어떤 노드의 값을 증가시키는 작업
(Min Heap 에서는 decrease value)
- Heap 속성을 위배하는 경우, 부모 노드의 값이 더 커질 때까지 부모 노드와 값을 바꾸는 작업
2) Heapify 작업 필요 X
- Max Heap 구조에서는, 노드의 값을 증가시켜도 항상 자식 노드보다 크다는 것이 보장
- Min Heap 구조에서는, 노드의 값을 감소시키면 항상 자식 노드보다 작다는 것이 보장
(2) 작업(수행) 순서
1) 어느 노드의 값을 증가
2) 부모 노드와 비교하여, heap 속성을 위배하는 경우 부모 노드와 값을 바꿈
3) 힙 속성이 유지될 때까지 2번 작업 반복

6. Insert
(1) 개념
- 힙에 요소를 삽입하는 작업
(2) 작업(수행) 순서
1) 힙의 끝에 최솟값 삽입
2) Increase Value 함수 호출 -> 추가된 값을 삽입할 값으로 증가 & 힙 속성 유지

[Step 1] 힙의 끝에 최솟값 삽입
[Step 2] Increase Value 함수 호출
- 위의 예시에서, 추가된 값을 17로 증가
- 증가한 노드 값을 부모 노드 값과 비교 -> 부모 노드의 값이 더 작은 경우 교환
(3) 시간 복잡도 : O(logN)
7. Delete
(1) 개념
- 힙에서 요소를 삭제하는 작업
(2) 작업(수행) 순서
1) Increase Value 수행 -> 삭제할 요소를 Max 값으로 증가 -> 루트 노드에 위치
2) Extract 수행 -> 루트 노드에 값을 추출

[Step 1] 삭제할 값에 대해 Increase Value 수행
- 위의 예시에서, 노드 15의 값을 MAX 값으로 증가 후 -> 루트 노드에 위치
[Step 2] Extract 수행
- 힙의 마지막 요소 13을 루트로 이동 -> 루트 노드부터 Max Heapify 수행
(3) 시간 복잡도 : O(logN)
참고
'Programming > Algorithm' 카테고리의 다른 글
| [Algorithm] 비트마스킹(Bit Masking) (0) | 2022.06.25 |
|---|---|
| [Algorithm] 프로그래머스 전화번호 목록(해시) (0) | 2022.05.13 |
| [Algorithm] 백트래킹(Backtracking) (0) | 2022.02.27 |
| [Data Structure] 트리(Tree) 자료구조 (0) | 2022.02.14 |
| [Algorithm] DP(Dynamic Programming) (0) | 2022.01.15 |


